Build to Survive
A discussion on why teams should wait to optimize for scale until after launch.
Startups are a funny thing. Usually they fail, but sometimes they don't. As the tech lead of a new web service, you need to somehow balance getting this thing to market in a timely manner while also making sure it stays online once it does. The latter seems to be a source of much anxiety for contemporary engineering leadership, so in today's piece I'm going to discuss why most teams should wait to build for scale until after launch. For the sake of discussion, let's consider "building for scale" to mean building web services to withstand the potential load of the core product achieving considerable market saturation.
It may be constructive to start with a brainstorming session in which we consider the challenges related to scaling from day one. Let's just say that your hypothetical startup is well-funded. Even so, hiring is a hard problem, and building for scale requires bringing in a wider variety of talent. Perhaps that means backend engineers with microservice experience. Are you doing event streaming, gRPC, or a hub-and-spoke Redis approach? Will you need a Kafka cluster? More infrastructure means more time spent on devops. If we want autoscaling infrastructure via Kubernetes or a cloud offering, then full-time devops support may even be required. Self-hosting containers is rather trivial in comparison. Then there's the frontend. Will HTML stream directly from the backend, or will the frontend be split into a separate service? Dividing frontend and backend may make it possible to assign more engineers to a project, but if you aren't hiring them right away then your current engineers will be saddled with more work in the meantime. Building for scale is complex, and complexity always comes at a cost.
Building a web service to scale from scratch is also prone to failure. Optimizing beyond base performance needs so early is bound to look a bit like dousing. For those unfamiliar with the practice, this involves taking two sticks, holding them in front of you with a loose grip, and walking about until they cross. X marks the spot of your new well. Of course, this is silly, and the outcome of finding a good well spot with this method is random. As a web service grows up, it could experience growing pains in any part of the infrastructure: the database, the workers, the web server, the load balancer, external APIs, and so on. Each software component may also fail due to saturation of all different kinds of physical resources (e.g., CPU, GPU, memory, file storage, and network). At such an early point in development, it will be difficult to predict what exactly is at risk of outgrowing its theoretical limits. With so many different areas to focus on for scaling, and each area requiring resourcing to build around, picking a scaling strategy from the outset is unlikely to yield positive results.
Day one is also the worst possible time to build for scale because it's when you need to be building actual features. Consider the following graph:
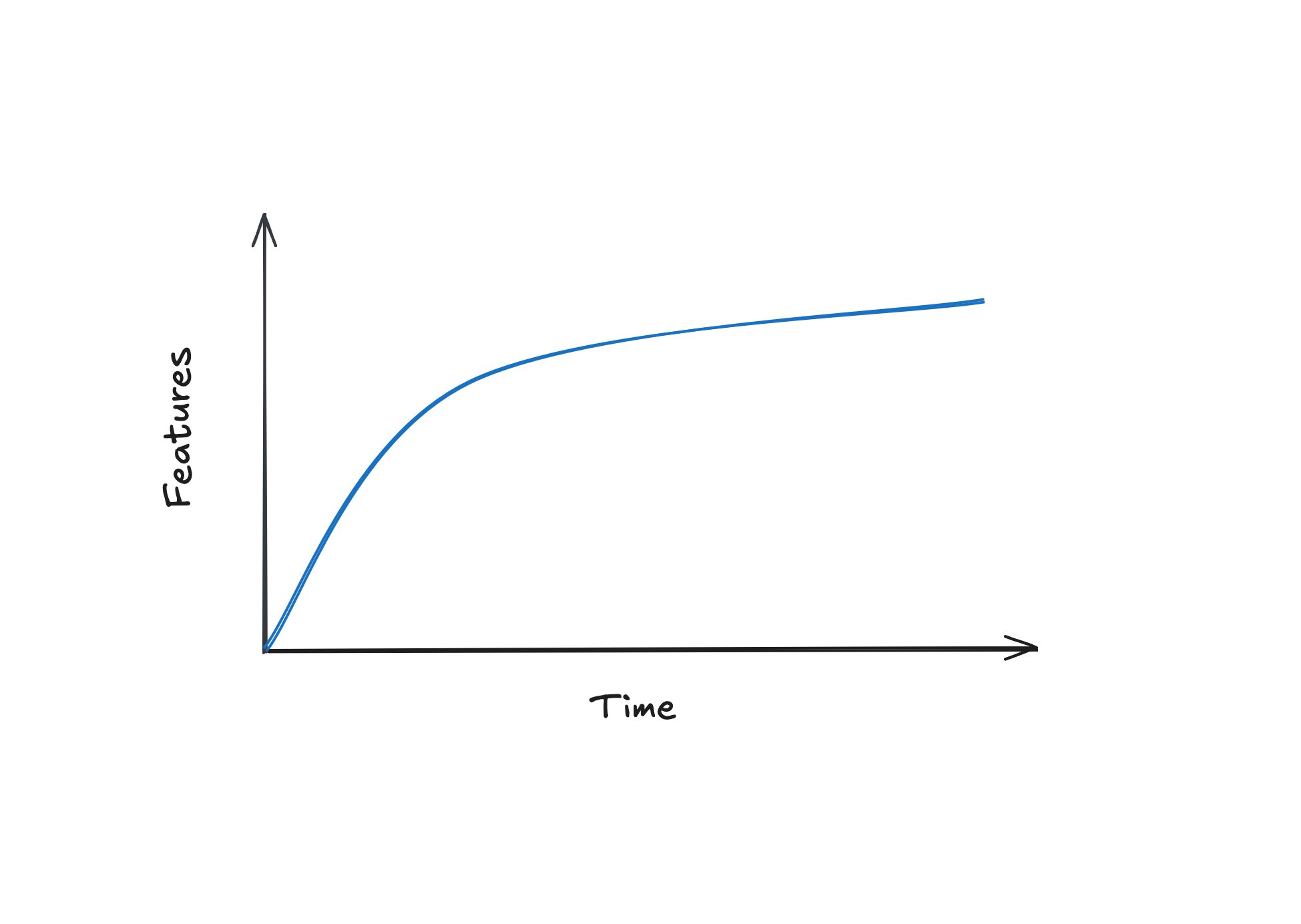
The above graph represents feature growth in the typical software product over time. The exact trend line for your product may differ, but this will do for illustrating my point. When development starts, your team is under maximum pressure to implement features. Any time spent engineering solutions to scale on day one is time not spent preparing the actual product for launch. As time goes on, the need for new feature development tapers off, and team capacity for working on optimizations increases.
Okay, so if not on day one, when does a team need to transition into work on scaling? The answer is actually pretty straightforward: work on scale when there are signs that a system needs to change. So, there is actually some additional work that needs to be done very early in the development process to support this, which is setting up the necessary telemetry to inform you of when problems are on the horizon. The big cloud providers all provide metrics around virtual resource utilization. If you have analytics, look at response times. Tracing is also extremely useful for gauging performance. Orient the engineering culture around fact-based optimization. Chart your key metrics and use them to predict which specific parts of the system will need changes in the next year. Do not extrapolate complex performance changes to areas of the software that lack indications of needing them. In the absence of concerning metrics, prefer to optimize for development speed over scale, because you won't need scale if you can't make it to market.